[JupyterNotebook] 데이터 저장 JupyterNotebook에서 데이터를 저장하는 방법to_csv를 통해 데이터 프레임을 csv파일로 저장할 수 있다.이 때 저장 경로는 JupyterNotebook파일의 위치이며, data/를 이용해 data 폴더로 옮긴후 저장하였다.데이터를 불러오는 방법은 read_csv를 통해 csv 파일을 불러올 수 있으며 이 때도 역시 /를 이용해 특정 폴더에서 불러오기 할 수 있다. Python 2024.11.02
[JupyterNotebook] 중복 데이터 중복데이터의 발견 및 삭제 방법우선 중복데이터가 들어가있는 데이터 프레임을 하나 생성하였다.중복값은 duplicated를 이용하면 찾을 수 있다.기본적으로 모든 값이 같아야 중복값으로 체크하고, 특정 열만 기준으로 중복값을 잡고싶다면 duplicated(subset="[]")을 이용해야한다.중복값 행데이터를 전부 보고싶다면 다시 데이터 프레임처럼 만들어서 볼 수 있다.df[df.duplicated]를 사용하면 True인 값을 반환하므로 두번째부터 나타나는 중복데이터를 데이터프레임으로 볼 수 있다.원본까지 보고싶다면 keep=False를 이용하여 원본데이터도 볼 수 있다.중복값은 drop_duplicated로 삭제할 수 있다.이 때 중복된 값들 중 하나만 남기고 나머지가 제거된다.기본적으로 원본 데이터가 .. Python 2024.11.01
[JupyterNotebook] 통계함수 기본 오늘은 통계함수에 대해 알아보자.통계함수는 데이터의 내용을 간략하게 보여주는 방법이다.describe를 통해 모든 기초통계가 확인이 가능하다.count, mean, std, min, max, 25%, 50%, 75% 등 다양한 통계를 제공한다.문자가 혼합되었을 때 describe를 통해 통계를 받으려고 하면 문자열을 제외한 수치열에서만 통계를 제공한다.문자열 통계는 다른 방법으로 확인할 수 있다.describe(include=["object"])를 이용한다면 문자열 데이터에 대한 통계만 반환한다.count, unique, top, freq를 반환해준다. Python 2024.10.31
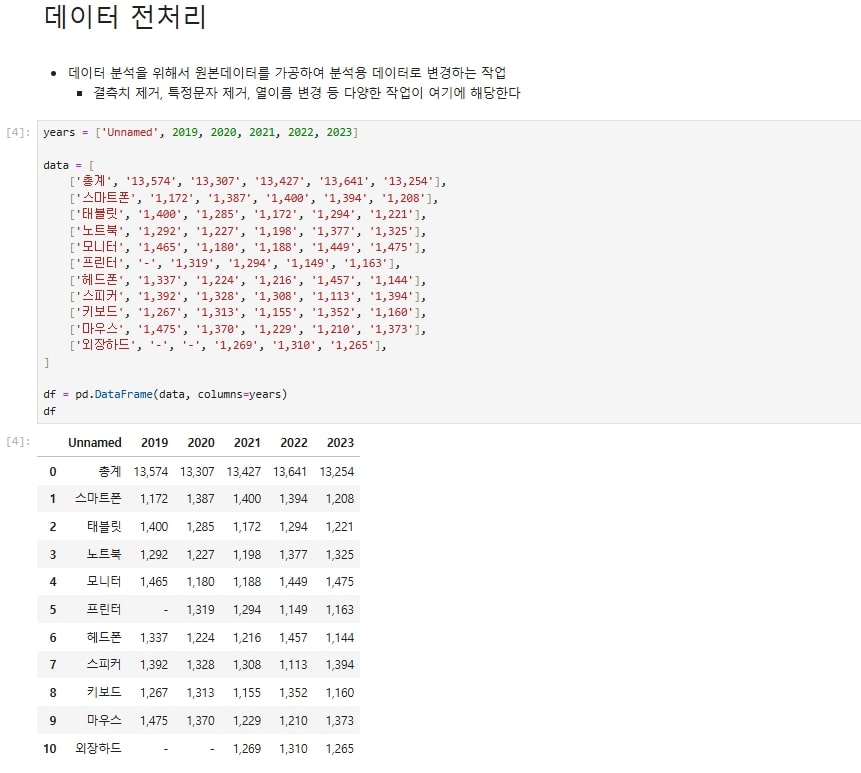
[JupyterNotebook]데이터 전처리 데이터를 받을 때 항상 숫자열에 숫자만 있고 결측값이 없이 깔끔하지는 않다.그래서 데이터 분석을 하기전에 전처리를 진행해주어야한다.데이터 전처리 과정들을 간략하게 알아볼 것이다.데이터를 일단 간단하게 생성하여 데이터 프레임으로 만들었다.이름이 지정되지 않은 Unnamed를 품목/년도로 새로 지정하여 모든 열이 제대로 된 이름을 가지도록 변경해주었다.결측치인 -를 0으로 변환하여 결측값이 없도록 변경하였다.숫자에 들어간 ,를 제거하여 숫자열에서 숫자만 남도록 변경하여 수식을 사용할 때 문제가 없도록 변경하였다.인덱스가 비어있는데 이것을 품목/년도를 인덱스로 사용하도록 변경하여 데이터 전처리 과정을 끝냈다. 카테고리 없음 2024.10.30
[JupyterNotebook]데이터 병합 어제 데이터 병합을 하는 방법인 concat을 잠깐 보았다.데이터 병합에 대해 좀 더 자세히 알아보자.기본적으로 concat은 행단위병합이다.열이 동일한 두 데이터 프레임을 간단하게 합칠 때 사용한다.행의 개수가 똑같고 다른 데이터 프레임과 서로 연관이 있을경우 axis를 이용해서 열단위로도 병합이 가능하다.이 때 열의 순서를 새로 지정할 수 있다.서로 열과 행이 다르고 한가지 열에서 데이터가 동일할 경우에는 위의 방법으로 병합을 하기가 힘들다.그래서 merge를 사용한 Join을 하게된다.기본적인 Join은 Inner Join이며 조인키를 기준으로 첫번째 데이터프레임에 두번째 데이터프레임을 병합한다.Left Join과 Right Join은 조인키가 없어도 병합이 가능하며, 각 데이터에서 없는 값은 빈칸.. Python 2024.10.29
[JupyterNotebook]Unpivot Unpivot은 Pivot의 반대작업이다.수집해서 분석용 데이터로 만들었던 것을 다시 원래의 데이터 형태로 변환해 다른 분석데이터를 만들거나 새로운 데이터를 추가할 때 주로 사용하는 방법이다.데이터 프레임을 간단하게 만들어 봤다.stack을 이용하면 시리즈데이터로 다시 변환한다는 것을 알 수 있다.JupyterNotebook에서 Unpivot은 stack과 reset_index를 이용하여 할 수있다.다시 원래의 데이터로 돌아가고 열이름은 기본적으로 level과 숫자로 조합되기 때문에 열이름을 새로 부여해주어야한다.새로운 데이터를 만들어서 concat함수를 이용해서 병합하였다.데이터 병합에 관련된 것은 내일 더 자세히 알아볼 것이다. 지금은 concat이 병합을 해준다는 사실만 알고있자.새로운 데이터를 추.. Python 2024.10.28
[JupyterNotebook]Groupby Groupby함수는 특정 열을 기준으로 데이터를 그룹화하여 특정 그룹을 만들어 집계연산을 할 때 주로 사용한다.Groupby로 index를 성별로 value값을 점수로하여 집계함수를 이용해 데이터를 새로 제작Groupby함수도 Pivot처럼 멀티 인덱스가 가능하다.aggfunc함수를 사용했던것을 Groupby에서는 agg를 이용하여 여러가지 집계함수를 사용하도록 할 수 있다.Groupby를 Pivot_table로 표현하면 이런식으로 표현할 수 있다.멀티 인덱스를 사용하고 싶으면 index에 []를 사용하여 리스트로 변환하면된다. Python 2024.10.27
[JupyterNotebook]Pivot Pivot은 기존 열을 이용해 데이터를 재해석하는 방법이다.특정 열을 참고하여 그 열을 인덱스로 만들고, 칼럼을 새로 지정하는 등 데이터프레임을 변환시킬 수 있다.학생 성적 데이터프레임을 만들었다.이를 통해 Pivot을 써보자.Pivot을 사용하여 index를 반등수, columns을 새로 반으로 지정했다.value값은 이름 및 점수를 사용하였다. 이처럼 특정 열들을 이용하여 새로운 데이터 프레임을 생성가능한 것이 Pivot함수이다.이를 통해 데이터에서 특정 구간만 긁어와 새로운 데이터 프레임을 생성하는 것이 가능하다.Pivot_table함수를 사용하여 aggfunc를 이용하면 집계함수를 사용이 가능하다.상위 인덱스를 추가하기위해 학년을 추가하였다.이 인덱스를 기점으로 그 뒤의 반을 분류할 수 있다. Python 2024.10.26
[JupyterNotebook]정렬 시리즈와 열을 오름차순 및 내림차순 정렬이 가능하다.시리즈에서는 내부의 값 뿐만아니라 index값도 사용하여 정렬이 가능하다.기본적으로는 오름차순 정렬이며, ascending=False를 이용하여 내림차순으로 변경 가능하다.특정 열을 기준으로 정렬을 진행할 수 있다.이 때 여러 열을 기준으로 정렬할 수도 있으며, 이 때에는 먼저 나온 열을 먼저 정렬한 후 같은 값이 있다면 다음 열에서 정렬을 한다.두 열의 기준을 오름차순, 내림차순 다르게 지정할 수도 있으며, 이 때 ascending을 리스트 형식으로 하여 True 및 False를 지정해줘야 한다. Python 2024.10.25
[JupyterNotebook]열 필터링 및 결측값 처리 데이터를 필터링하여 특정 열을 가져올 수 있다.특정 열을 지정해서 필터링하거나 특정 문자열이 포함된 열을 필터링할 수 있다.결측값이 있는 모든행을 isnull과 any를이용하여 결측값이 있다면 True로 반환해준다.그것을 이용해서 True 결과값만을 가지는 모든 열을 반환하도록하여 결측값이 있는 모든 열을 받아올 수 있다.결측값이 존재하는 모든 행은 axis=1를 이용하여 추출이 가능하다.sum을 통해 결측값을 모두 더해 열마다 결측값이 얼마나 많은지도 확인이 가능하다.dropna를 이용하여 value_counts에 결측값을 추가 가능하다결측값은 보정이 가능하다.특정 배열을 가진 빈 칸, 선형데이터 빈 칸 및 점수 결측치 등은 배열, 선형데이터의 중간값, 0점처리등 다양한 방법으로 결측치를 변경하는 것이.. Python 2024.10.24